
Soooo… you’ve decided you’re going to create a system-on-chip (SoC) device of such awesomeness that it will leave your competitors gnashing their teeth and rending their garb. You’ve also decided to base this on a RISC-V processor. What you want is the biggest, baddest RISC-V processor going. Furthermore, you want this processor to be customized to allow you to take full advantage of your own “secret sauce” IP. Who ya gonna call?
I’ll give you a clue, which is that the Ghostbusters aren’t going to be of much help in this case. But turn that frown upside down into a smile because the guys and gals at Semidynamics Technology Services are ready to leap into action.
I was just chatting with Roger Espasa, who is the Founder and CEO at Semidynamics, and I now know more about customizing RISC-V cores than I ever expected.
Just to provide a little background, Semidynamics was founded in 2016. The folks at Semidynamics spent the first two and a half years offering design services before transitioning to offering IP. Although they are based in Europe, they also have customers in the US and Asia. In addition to their customizable RISC-V processor cores, they lay claim to offering the only and biggest out of order (OOO) RISC-V vector unit.
Yes, of course you are correct. If they are offering the only OOO RISC-V vector unit, then it is—by definition—the biggest, but dare I suggest you are being a tad pedantic to point this out?
The Semidynamics business model is reasonably standard. If you request any changes to the cores, you will be charged NRE accordingly. Once any such customizations have been implemented, you will be provided with a corresponding bitstream for the FPGA of your choice, thereby allowing you to verify that your spiffy new custom core is all you wanted it to be. If you are happy (and Roger says that, thus far, their customers have always been happy), you’ll sign a license to tape-out, they will give you the RTL for your core, and they will support you all the way through the tape-out process (their cores have been implemented at the 22, 12, 7, and 5nm process nodes).
Before we plunge headfirst into the fray with gusto and abandon (and aplomb, of course), let’s start by briefly introducing four names and icons as follows:
![]()
Meet the processor cores and related technologies (Source: Semidynamics)
If you just need a regular mid-range-performance processor, then the 64-bit in-order Avispado—which means smart, fast, and witty in Spanish—is the one for you. This is available as a 2-wide processing unit, which means it can perform two operations on each clock.
By comparison, if your application demands more extreme processing capability, then you will want to be looking at the 64-bit out-of-order Atrevido, which means daring, courageous, and bold in Spanish. This bodacious beauty is available in 2-, 3-, and 4-wide configurations.
High-level block diagrams for the Avispado 223 and the Atrevido 423 are shown below. As opposed to many companies’ numbering schemes—the attempted understanding of which makes one’s brains leak out of one’s ears—the approach adopted by Semidynamics is a delight. In addition to the fact that the Avispado and Atrevido monikers immediately inform that you are talking about in-order or out-of-order, respectively, the first number specifies the width while the last two numbers indicate the year, so the Avispado 223 is an in-order 2-wide processor that was presented to the market in 2023, while the Atrevido 423 is an out-of-order 4-wide processor that bid the market a cheery “hello” in 2023.
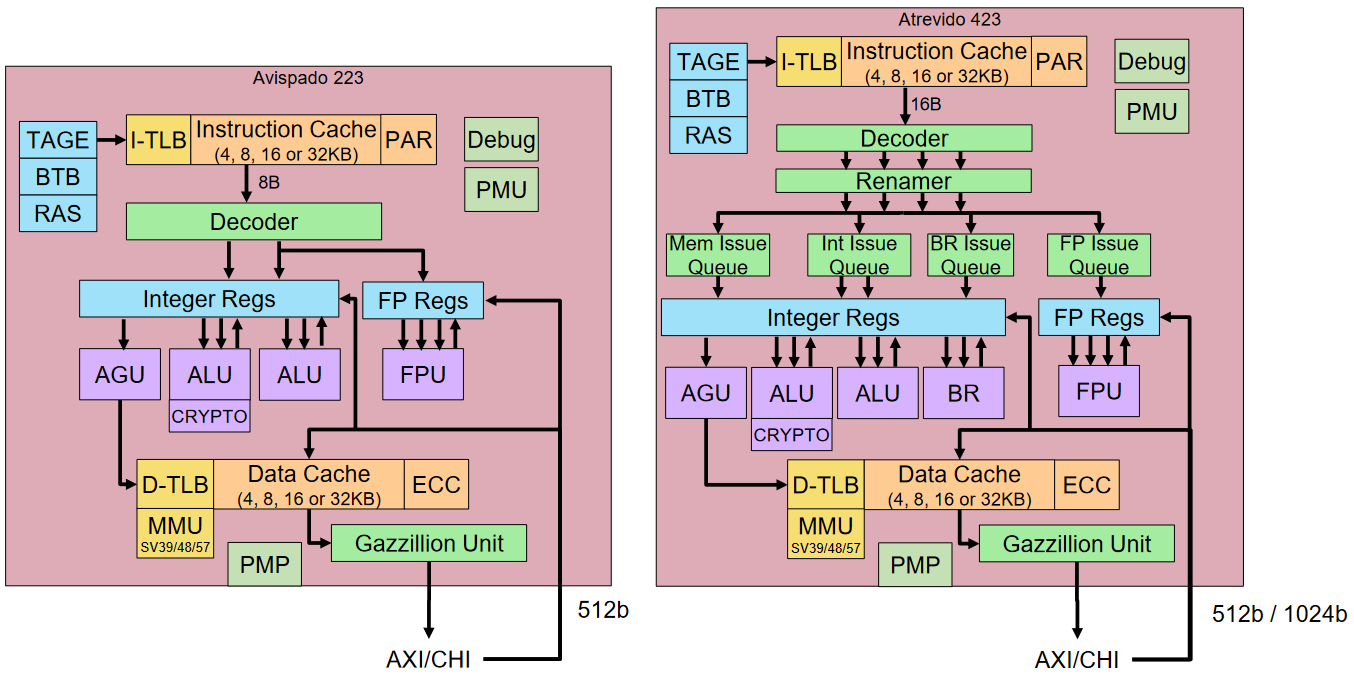
High-level block diagrams for the Avispado 223 (left) and the Atrevido 423 (right) (Source: Semidynamics)
Both of these processors are available in two flavors—with an AXI interface for people who don’t need coherency and with a CHI interface for those who do. Both processors include a Gazillion Unit (shown in the block diagrams above), which dramatically improves memory accesses. And both processors can be augmented with the aforementioned OOO vector unit (not shown in the diagrams above, so you can stop looking for it). We’re on a roll here because both processor types also offer the following:
- User, Supervisor, and Machine privilege levels.
- Hypervisor available in Q4 2023
- Linux-ready memory system with a memory management unit (MMU) (supports SV39/48/57), coherent caches with parity of ECC, and hardware support for atomics and unaligned accesses.
- PMP regions (0 to 16).
- Advanced debug capabilities (RISC-V debug spec compliant interface over JTAG and HW/SW breakpoint support).
- RISC_V extensions supported: Vector, Crypto, Bit Manipulation, CMOs, Zifenci.
- Quad-core ready.
Roger says that, like other vendors, the folks at Semidynamics can easily change obvious things like cache sizes and bus sizes. Where Semidynamics differentiates itself is that they are willing to make much more complicated and radical changes. For example, if you want to connect something right in the middle of the MMU unit to implement some funky loads that do “I don’t know what” for your special computing needs, the team will happily do this for you (this is why they describe themselves as being “Experts in open core surgery”).
Observe the Gazillion unit in the block diagrams above. Roger says this is something that they’ve worked very hard on. The idea is that we want the core to stop as little as possible and Gazillion helps to avoid latency issues when accessing off-chip memory. In contrast to traditional processors, which employ a “stop-and-go” operating mode when encountering multiple cache misses, Gazillion technology allows the processor to send up to 128 requests to the memory system, thereby allowing the processor to continue to do useful processing while previous misses are served. To put this into perspective, the figure below compares the Gazzillion technology in the Atrevido and Avispado cores to other popular cores available in the market.
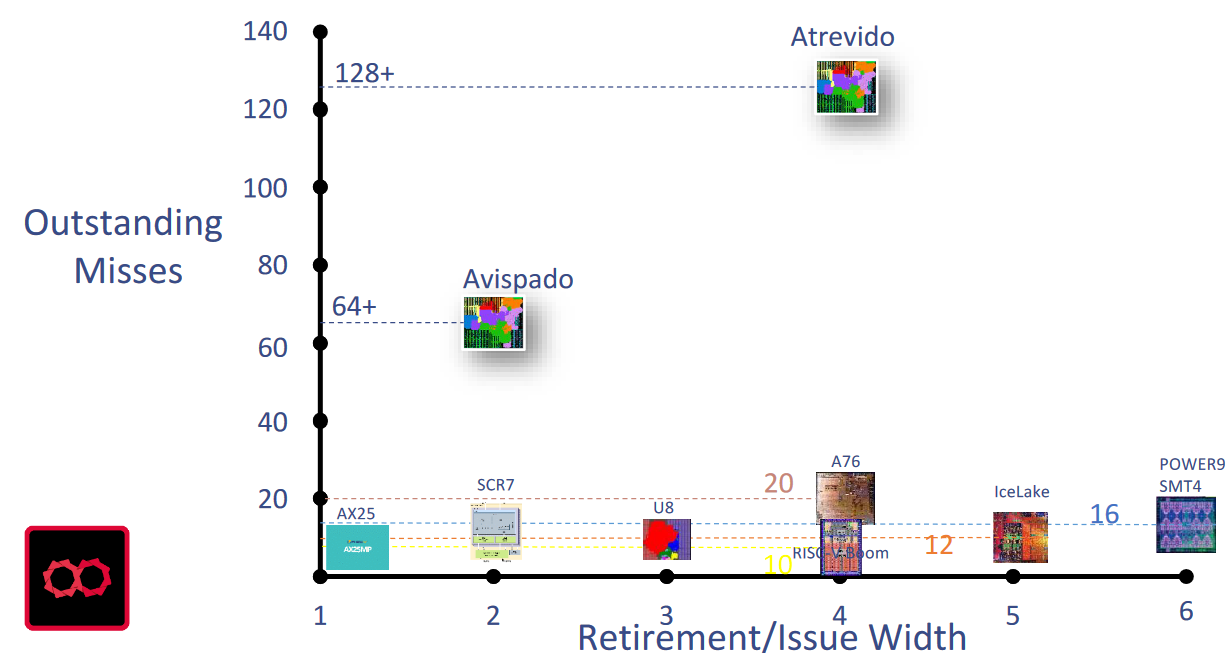 Gazillion compared to other CPUs (Source: Semidynamics)
Gazillion compared to other CPUs (Source: Semidynamics)
And so, finally and inexorably we find ourselves at the point in our discussions when we turn our attention to the optional OOO vector unit we made mention of earlier. Let’s start by noting that this little rascal is 100% customizable according to your needs. Customization #1 is to choose between V4, V8, V16, and V32 options, which have 4, 8, 16, or 32 vector cores, respectively.
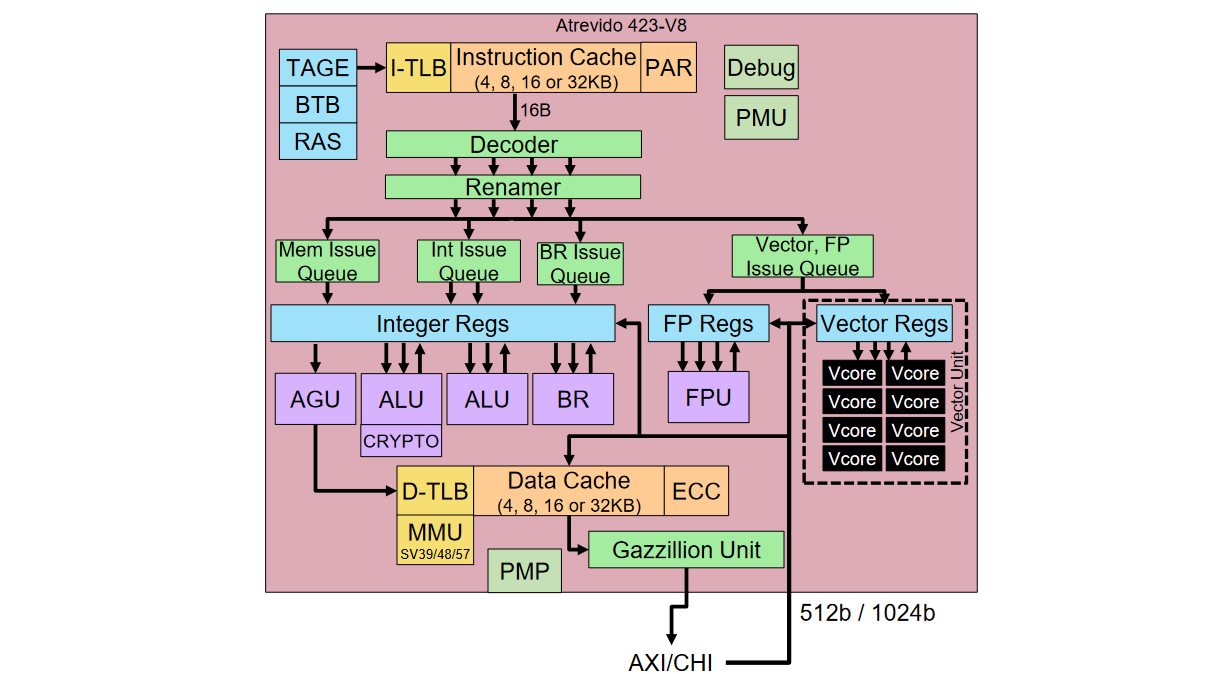 Atrevido 423 + V8 Vector Unit (Source: Semidynamics)
Atrevido 423 + V8 Vector Unit (Source: Semidynamics)
Customization #2 is to select the data types you wish to support out of INT8, INT16, INT32, INT64, BF16, FP16, FP32, and FP64. If your SoC is intended for high-performance computing, then you’ll probably want your vector unit to support the whole shebang up to and including FP64. If Oil and Gas is your bag, then FP32 and its friends may be all you need. Or, if you are more focused on artificial intelligence (AI) and machine learning (ML), it may be that FP32 and INT8 will suffice.
But wait, there’s more, because Customization #3 lets you decide on your vector register length—options are 1X, 2X, 4X, or 8X the number of vector cores—which is great when it comes to increasing performance and reducing power consumption.
One last point here is that you may wish to connect the vector unit to your own “secret sauce” IP block, but you don’t want to share any information as to what’s in your IP. No problemo, because the folks at Semidynamics provide a very simple protocol they call their “Open Vector Interface” that allows you to do your “thing” without telling anyone else just what it is you are doing.
There’s so much more to all of this, but I fear I cannot do it justice, so if you wish to plunge deeper into the techno-details, please reach out to the folks at Semidynamics (don’t forget to tell them that “Max says ‘Hi’”). In the meantime, as always, I’d love to hear any thoughts you’d care to share in the comments below.
Leave a Reply
You must be logged in to post a comment.