
Just to make sure I have your attention, let’s start with the conclusion and then I’ll tell you how we got there. Is that OK with you? Good. In that case, the conclusion is that the clever folks at CacheQ have come up with a cunning solution that can take your regular single-threaded C/C++ code and compile it in such a way as to achieve multi-threaded acceleration on CPUs with multiple physical cores, all without any effort, pain, tears, trials, or tribulations on your part. Interested? If so, read on…
Let’s start with the fact that I love processors based on the von Neumann architecture — CPUs, MPUs, MCUs, and so forth (see also What the FAQ are CPUs, MPUs, MCUs, and GPUs? and What the FAQ are ASICs, ASSPs, SoCs, SOMs, etc.?). Having said this, although these processors are extremely clever, and while they are wonderful with regard to performing decision-making tasks, they tend to be horribly inefficient when it comes to accomplishing many data processing algorithms.
The problem in a nutshell is that these processors — and the high-level languages (HLLs) used to program them (e.g., C and C++) — are inherently sequential in nature, which means they plod along performing one simple operation after another. The reason these little rascals appear to be so fast and powerful is that we ramp up the clock rate, forcing them to perform hundreds of millions, or billions, of these simple operations each second. Unfortunately, the amount of power they consume rises as a square of their core clock frequency. As a result, you could easily get a first-degree burn by removing the heatsink on a CPU in a personal computer, workstation, or server and then touching that CPU (this would occur shortly before the system shut down and/or caught fire).
By comparison, the programmable fabric in FPGAs allows appropriate data processing algorithms to be executed in a massively parallel fashion, thereby allowing the same amount of processing to be performed using significantly lower clock speeds and consuming considerably less power, or dramatically increasing the amount of processing that can be achieved while consuming the same amount of power.
The obvious solution is to take the original C/C++ program, profile it to see where the bottlenecks are, and then partition things such that the slow and steady decision-making control code remains running in the CPU, while the fast and furious compute-intensive data-processing algorithms are dispatched to run on hardware accelerators implemented in an FPGA’s programmable fabric. Unfortunately, like most things, this sounds easy if you talk loudly and gesticulate furiously, but it’s a lot harder to implement than you might think. First, we are going to require some way to interface the software and hardware portions of the algorithm, where the type of interface we use (DMA, FIFO…) will be influenced by the profile of the data we wish to hurl around. Also, traditionally, the hardware accelerator in the FPGA would need to be implemented by an FPGA hardware design engineer. In turn, this meant the software and hardware folks were required to communicate with each other, which historically has not proven to be as efficacious as one might hope.
The ideal solution would be for a special software platform to perform the vast majority of the work, including taking the C/C++ source code, compiling it, profiling it, optimizing it, and partitioning it. This platform would then output those portions of the design that are to be run on the processor, along with those portions of the design that are to be run in the FPGA, where the latter would be in the form of a hardware description language (HDL), like SystemVerilog, that would be synthesized to generate a configuration file to be loaded into the FPGA. Oh yes, and this platform should also automatically generate any necessary interface software code and hardware logic necessary to allow the software and hardware to talk together.
All of which leads us to CacheQ. I first became acquainted with these guys and gals a couple of years ago circa 2019. At that time, they had come up with a solution to do everything we just discussed as illustrated below.
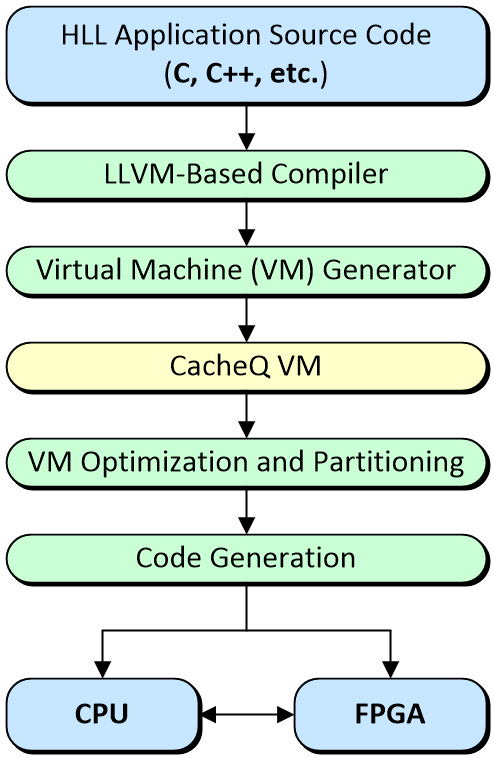
The CacheQ C/C++ to CPU + FPGA development flow
(Image source: Max Maxfield)
As I recall, their first-pass solution targeted desktop / workstation / server-class machines boasting X86 CPUs from Intel or AMD augmented with PCIe-based FPGA hardware acceleration cards supplied by FPGA vendors and others. Later, they added another string to their bow when they enhanced the system to include the ability to support heterogenous SoC FPGAs like Xilink’s Zynq devices, the high-end versions of which support multi-core Arm processors that communicate with programmable fabric by means of on-chip AXI busses. For example, the Zynq UltraScale+ MPSoC boasts dual or quad Arm Cortex-A53 cores, along with dual Arm Cortex-R5F cores, all augmented with humongous quantities of programmable fabric.
But Wait, There’s More!
Earlier, we alluded to the fact that some portions of our original C/C++ code may be optimally implemented by executing them in a sequential fashion on a traditional processor, while other portions of the code may be better served by realizing them in a massively parallel fashion in programmable FPGA fabric.
The thing is that there’s a third possibility. While some algorithms benefit from hardware acceleration, others may profit from running on multiple processor cores simultaneously. Now, remember that I’m a ruggedly handsome hardware design engineer, not a software development weenie, so please forgive any missteps in my terminology, but the idea is to take our single-threaded code and transmogrify it into a multi-threaded form that can take full advantage of multiple processor cores (these cores can be of the X86 flavor in workstations and servers, or they can be Arm or RISC-V cores lurking in embedded systems and skulking in FPGAs).
Traditionally, this has required a lot of work on the software developer’s part, including rewriting the code by hand, using special threading libraries, or employing complex parallel execution APIs such as OpenMP or MPI, which require the source code to be augmented by pragmas. Of course, it’s really embarrassing if you expend a lot of time and effort doing all this, only to come to the eventual realization that your code isn’t really suitable for multi-core processing in the first place.
Well, the clever chaps and chapesses at CacheQ realized that their tools already had the inherent ability to do all this for us. As a result, they recently announced support for multi-threading acceleration for CPUs with multiple physical cores through their new compiler, thereby offering software developers the ability to “write once, accelerate anywhere.” Equally valuable — if the code in question isn’t amenable to multithreading, the tool will tell you so. Even better, it will explain where the problems lie (data structures, indexing techniques…), because — if we’re lucky — it may be that some small tweaks will result in code that can be multithreaded.
This may be a good time for us all to feast our orbs on this short video in which we see the same original C/C++ application running on single thread compiled with gcc, then compiled to run on 1, 2, 3, and 4 threads/processor cores on a multi-core SoC FPGA. Finally, the exact same code is compiled using the exact same tool to run only in the FPGA’s programmable fabric.
I don’t know about you, but the fact that I can write some code knowing nothing about multithreading and then use CacheQ’s compiler and virtual machine to do all the threading for me — my only function (other than writing the code in the first place) being to specify the number and types of the processor cores — strikes me as being rather amazing.
And we are still only at the beginning of what’s possible. At the moment, for example, the options are (a) to take the original code and partition it into single-threaded code to run on a single processor core coupled with hardware accelerators implemented in an FPGA’s programmable fabric or (b) take the original single-threaded code and compile it into a multi-threaded equivalent that can take full advantage of multiple processor cores. If I were a betting man (“which, thank the Lord, I’m not, sir”), I’d wager it won’t be long before we see an option (c) that combines options (a) and (b). What say you? Do you have any thoughts you’d care to share on any of this?
Leave a Reply
You must be logged in to post a comment.